Продолжаем разбор стратегии надежности .
Ранее уже писал про
повышение надежности релизов и про
предотвращение инцидентов из-за потенциально известных проблем.
Сегодня - про реагирование на инциденты. Бывает такое - катишь взрывоопасный релиз и чувствуешь - вот-вот бахнет. Палец уже на кнопке отката, один глаз смотрит на деплой, другой - на дашборд. Тут вроде все понятно. Поэтому смотрим на все остальные ситуации.
У вас точно есть алерты. Много разных - на все случаи жизни. И сервисов тоже много, мы же делаем сложную распределенную систему. А там еще базы и балансеры - у них тоже ведро алертов. Само собой, при таком многообразии сигналов какой-то из них вот-вот да и вспыхнет. Но вы-то не первый день тут, вы пуганный. Ну загорелся какой-то алерт, делов. Вы наметанным глазом понимаете, что это не крит. А соседний алерт горит уже неделю, там известная проблема, не аффектящая пользователей, так что не страшно. Третий - уже давно замьючен, потому что фолсил. Так и живем.
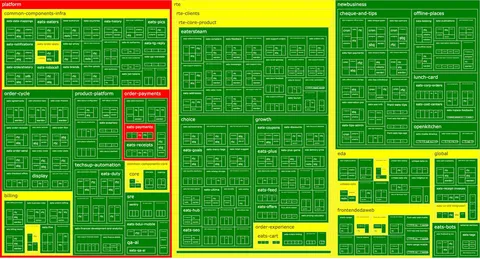
А не надо так. Привычное игнорирование некритичных алертов приводит к слепоте - вы не отличите крит от не-крита. Уже горящий алерт ярче не загорится, если системе станет реально хуже. Замьюченный - тем более. Вы летите без приборов и узнаете об инциденте из газет. Поэтому нужно держать высокий alerts uptime (доля времени, когда не горит ни один алерт, должна приближаться к желаемому аптайму системы в целом - 99.??). А еще полезно визуализировать это в виде полотна с плитками, где каждый не-зеленый кусочек должен вас искренне триггерить. Некритичные алерты нужно перенаправить куда-то в отдельный диагностический канал, а реально критичные - настроить так, чтобы их невозможно было не заметить.
Аналогия из автомобильного мира - лампочка check-engine (она же джеки-чан, она же мясорубка). Не понимаю людей, которые ездят с ней годами. Даже если зажглась она из-за ерунды, вы пропустите индикацию реально важной поломки. А заклеивают чек только перекупы. Я же на некоторых авто каждое утро начинал с подключения обд-сканера (elm) и сброса некритичных ошибок.
А что еще можно сделать, чтобы критичный алерт невозможно было бы не заметить? Во-первых, настроить хорошо эскалацию. В том числе телефонную. Чтобы если дежурный проспал, робот точно дозвонился бы до запасных персонажей вплоть до CTO. Во-вторых, автоматика должна инициировать протокол - создать чат, призвать дежурных, задать нужные вопросы. А если дежурный не пришел в протокольный чат - повысить северити инцидента и снова его эскалировать, включая уведомление в общие каналы коммуникаций, потому что что-то уже явно идет не так.
И про клиенты. У вас было такое, что по сигналам бекенда все хорошо, а фича не работает? Либо бек отдает 200 OK с пустым телом, либо схема ответа не соответствует контракту, причин масса. А приложению что-то не нравится. Тут главное - чтобы на клиенте это была не одна ошибка вида "ой, что-то пошло не так", а что-то осмысленное, с отправкой метрик и алертингом на них. Также стоит следить не только за синтаксическими, но и за семантическими ошибками. Например, синтаксически корректная, но пустая выдача - тоже сигнал.
Здоровья вашим сервисам, а если что-то все же бомбанет - не проморгайте. И не слепните.